Project: Dr. Semmelweis and the Importance of Handwashing
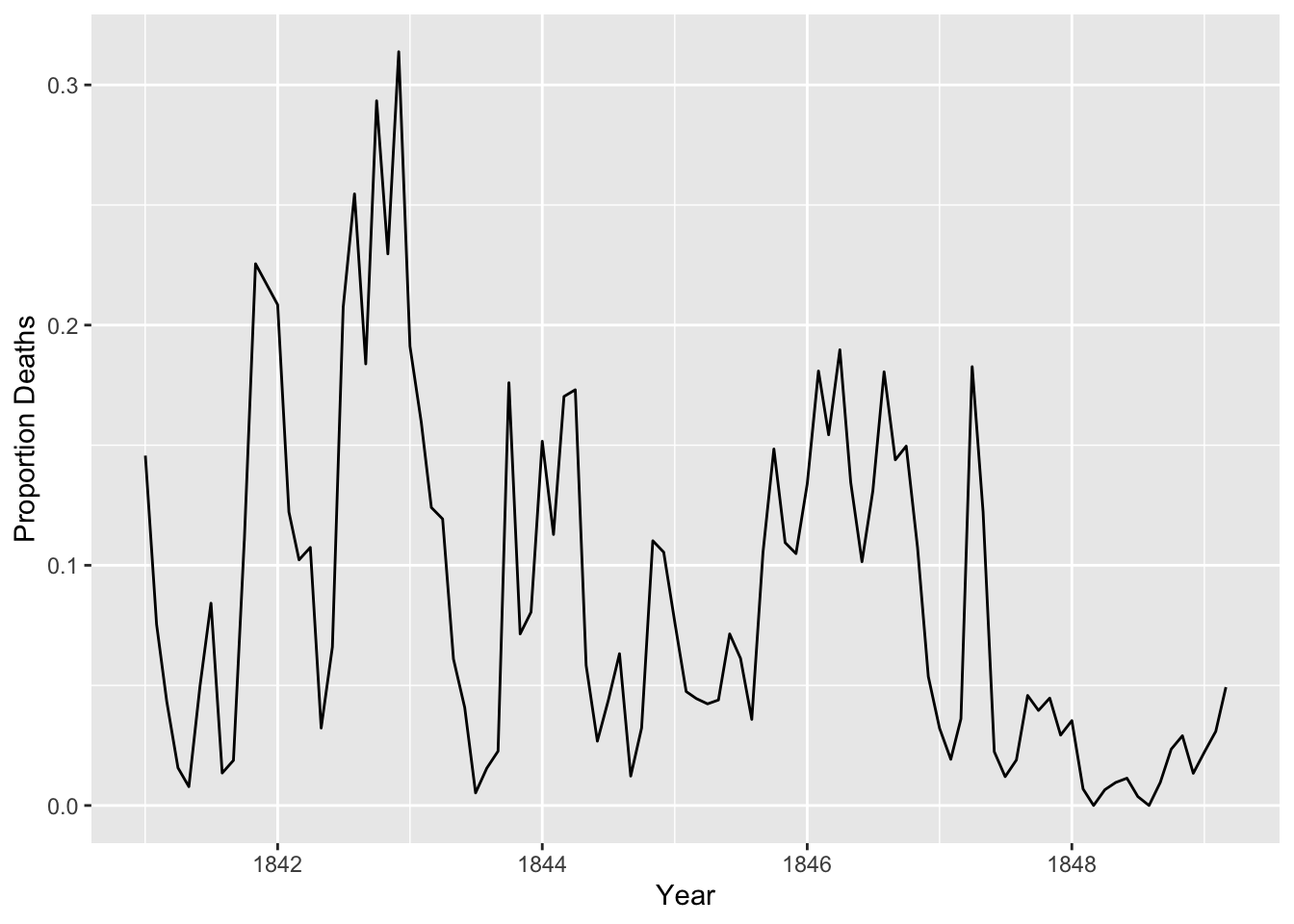
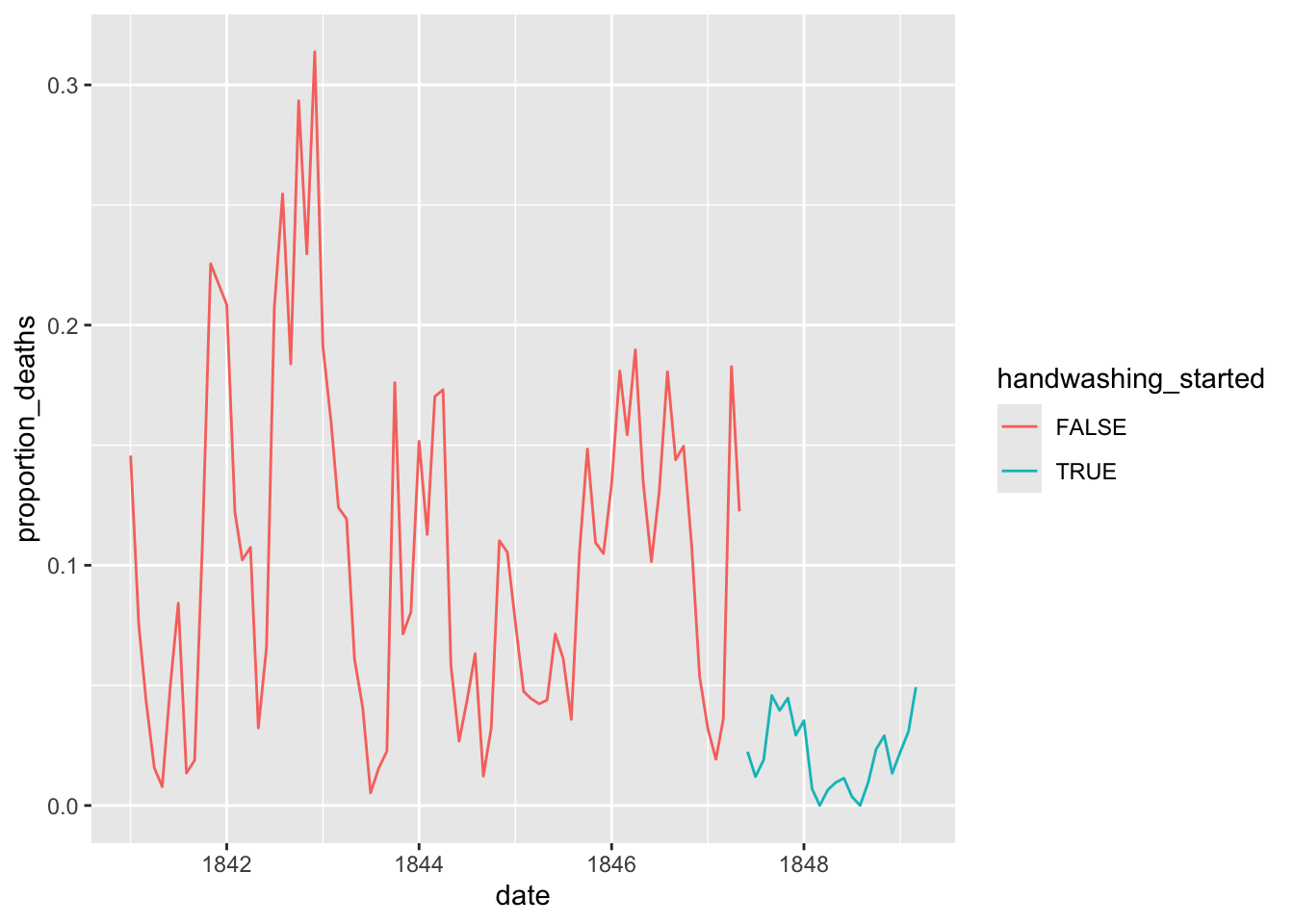
Hungarian physician Dr. Ignaz Semmelweis worked at the Vienna General Hospital with childbed fever patients. Childbed fever is a deadly disease affecting women who have just given birth, and in the early 1840s, as many as 10% of the women giving birth died from it at the Vienna General Hospital. Dr.Semmelweis discovered that it was the contaminated hands of the doctors delivering the babies, and on June 1st, 1847, he decreed that everyone should wash their hands, an unorthodox and controversial request; nobody in Vienna knew about bacteria.
You will reanalyze the data that made Semmelweis discover the importance of handwashing and its impact on the hospital.
The data is stored as two CSV files within the datasets folder.
yearly_deaths_by_clinic.csv contains the number of women giving birth at the two clinics at the Vienna General Hospital between the years 1841 and 1846.
Column
Description
year
Years (1841-1846)
births
Number of births
deaths
Number of deaths
clinic
Clinic 1 or clinic 2
monthly_deaths.csv contains data from ‘Clinic 1’ of the hospital where most deaths occurred.
Column
Description
date
Date (YYYY-MM-DD)
births
Number of births
deaths
Number of deaths
# Imported librarieslibrary(tidyverse)
Warning: package 'ggplot2' was built under R version 4.2.3
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.5.0 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
# Start coding here..
Load the CSV files
Load the CSV files into yearly and monthly data frames and check the data.
Rows: 12 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): clinic
dbl (3): year, births, deaths
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 98 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (2): births, deaths
date (1): date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Load and inspect the data#yearly = read.csv('datasets/yearly_deaths_by_clinic.csv') # R default function to read csv fileyearly =read_csv('datasets/yearly_deaths_by_clinic.csv') # read csv file function from tidyverse package
Rows: 12 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): clinic
dbl (3): year, births, deaths
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 98 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (2): births, deaths
date (1): date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Add a proportion_deaths column to each df, calculating the proportion of deaths per number of births for each year in yearly and month in monthly.[proportion_deaths = deaths / births]
# Add proportion_deaths to both data framesyearly <- yearly %>%mutate(proportion_deaths = deaths / births)monthly <- monthly %>%mutate(proportion_deaths = deaths / births)
Create two ggplot line plots
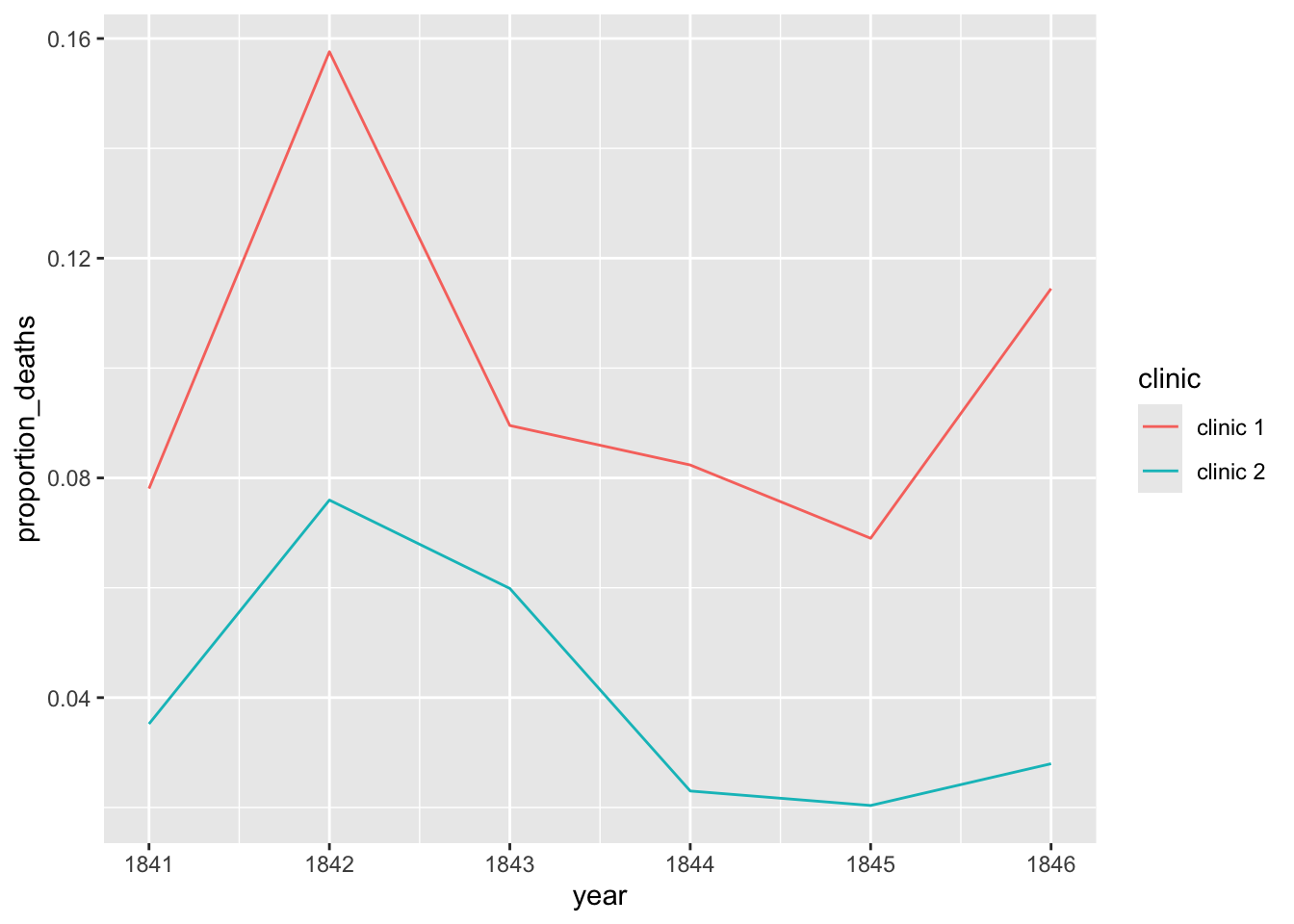
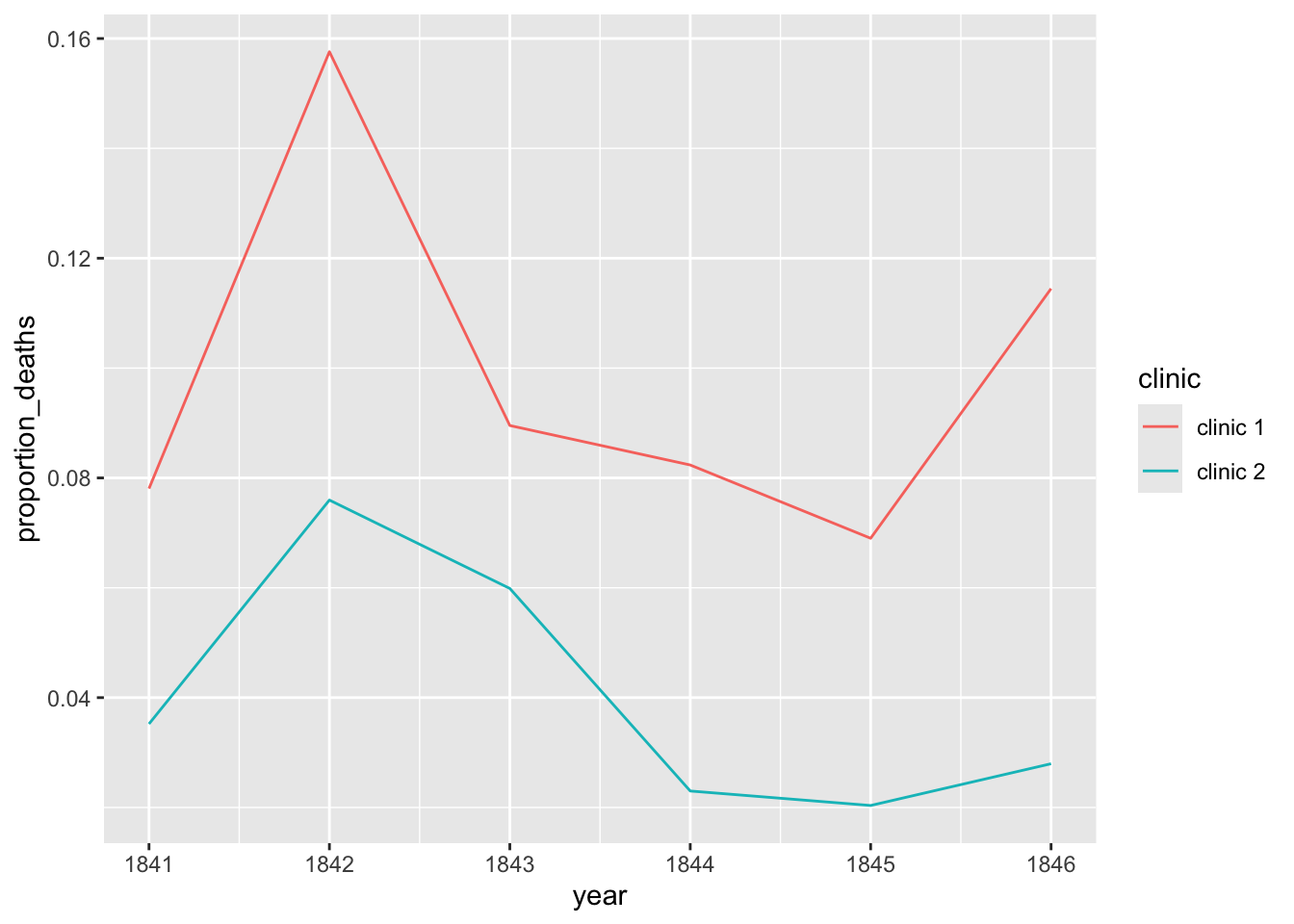
Create two ggplot line plots: one for the yearly proportion of deaths. Create a different colored line for each clinic.
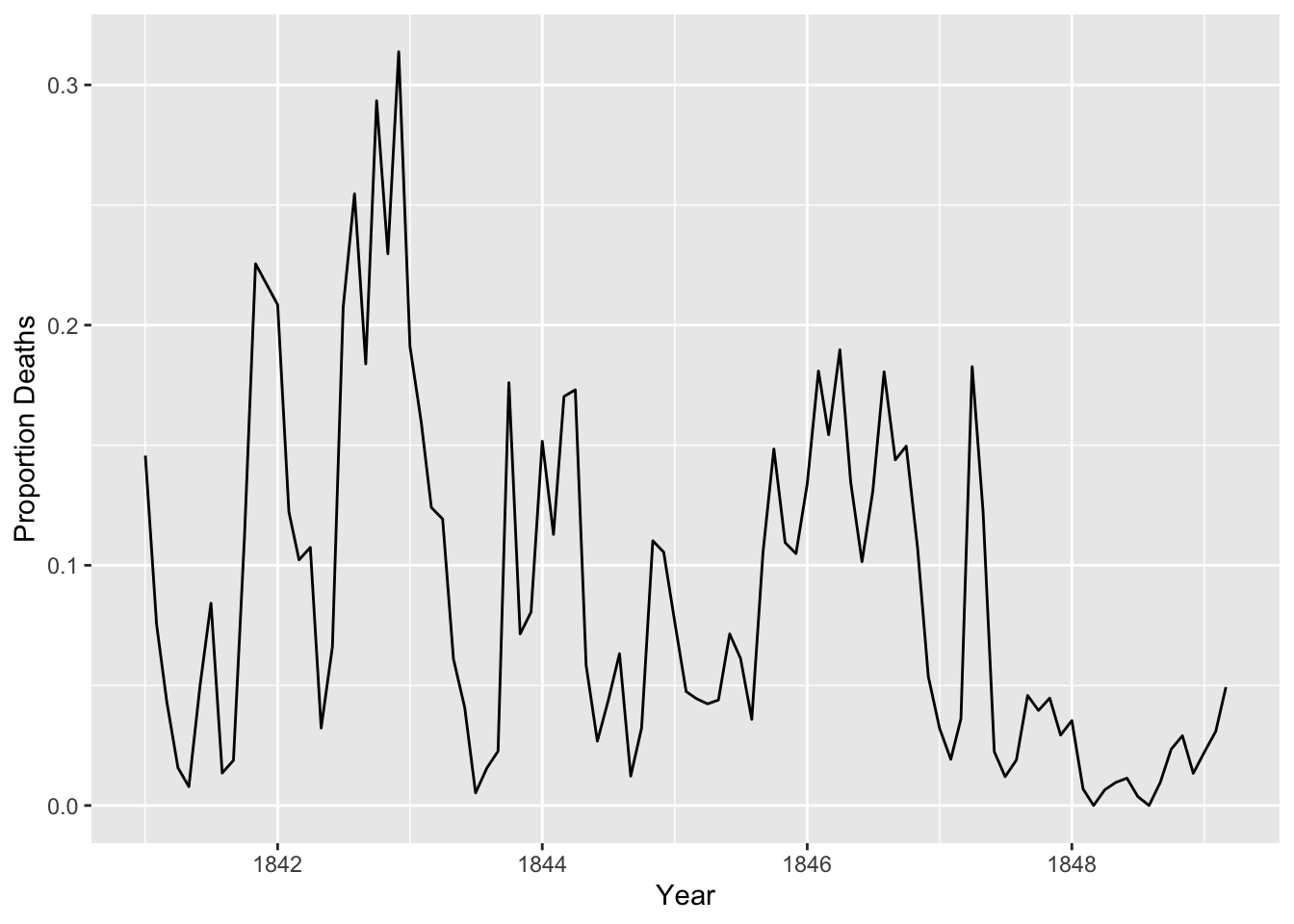
And another for the monthly proportion of deaths.
Answer
# Plot the dataggplot(yearly, aes(x = year, y = proportion_deaths, color = clinic)) +geom_line()
ggplot(monthly, aes(date, proportion_deaths)) +geom_line() +labs(x ="Year", y ="Proportion Deaths")
Add a handwashing_started boolean column and plot again
Add a handwashing_started boolean column to monthly using June 1st, 1847 as the threshold; TRUE should mean that handwashing has started at the clinic.
# Add the threshold and flag and plot againhandwashing_start =as.Date('1847-06-01')monthly <- monthly %>%mutate(handwashing_started = date >= handwashing_start)head(monthly)
Plot the new df with different colored lines depending on handwashing_started.
Answer
ggplot(monthly, aes(x = date, y = proportion_deaths, color = handwashing_started)) +geom_line()
Calculate the mean proportion of deaths
Calculate the mean proportion of deaths before and after handwashing from the monthly data, and store the result as a 2x2 df named monthly_summary with the first column containing the handwashing_started groups and the second column having the mean proportion of deaths.
Answer
# Find the meanmonthly_summary <- monthly %>%group_by(handwashing_started) %>%summarize(mean_proportion_deaths =mean(proportion_deaths))monthly_summary